
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 9663
- 8-queen
- 알고리즘
- 증가하는 부분수열 2
- 리스트
- 백준
- 대소비교
- 백준 1535
- 프로그래머스
- 백준 12015
- 파이썬
- python
- 2606
- 백준_2178
- 백준 2606
- 소수찾기
- LCS2
- boj 11053
- 12865
- BOJ 2606
- 데카르트 곱
- 냅색
- list
- 평범한 배낭
- dfs
- 백준 9252
- 가장 긴 증가하는 부분수열
- BFS
- 타겟 넘버
- 미로탐색
- Today
- Total
Devlog_by_0giru
[boj] 가장 긴 증가하는 부분 수열2_12015 본문
가장 긴 증가하는 부분 수열1 에 이은 시리즈 문제다.
처음에는 11053번처럼 dp로 접근하려고 했지만 입력 데이터의 수가 너무 많아 dp로 해결할 수 없는 문제임을 깨달았다.
dp를 이용하려면 전체 리스트(배열)에서 i번째와 i-1번째까지의 데이터를 중복해서 탐색해 O(N^2)의 시간 복잡도를 가지게 된다.
11053번의 경우 입력 데이터의 개수가 1000개 까지라 시간 초과에 걸리지 않지만 12015번의 경우 입력 데이터가 훨씬 많아 O(N^2)의 시간복잡도를 가진 알고리즘을 사용할 경우 시간 초과가 발생한다.
따라서 O(NlogN)의 시간 복잡도로 해결해야 하고 이를 위해 i-1번째까지의 데이터를 이진탐색을 통해 시간을 단축해줘야 했다.
사실 위 부분까지는 이해가 되는 부분이나, 아래 부터 나오게 되는 실질적인 구현 알고리즘은 이해가 어려웠다.
몇 시간을 이해하려고 고민해보다가, 11053번 dp풀이를 받아들인 것 처럼(...) 그냥 받아들이기로 했다.
보통 이해하기 어려운 것은 생소한 것이 많고, 시간이 지나 다시 보면 자연스럽게 이해하는 경우가 많더라.
이 문제를 풀기 위한 알고리즘은 아래와 같다.
1. dp처럼 입력된 데이터를 앞에서부터 순차적으로 비교한다.
2. 만약 새로 들어오는 값이 현재 증가 수열의 마지막 값보다 크다면, 그 값을 그대로 증가수열에 붙이면 된다. (자명히 증가수열이 될 것이므로)
3. 만약 새로 들어오는 값이 현재 생성된 증가 수열의 마지막 값보다 작다면, 그 값보다 작지 않은 최솟값과 치환한다. 이 때, 이 값을 빠르게 찾기 위해 이진 탐색을 이용한다.
내가 가장 이해하기 힘들었던 부분이 3번째 알고리즘이다. 이 알고리즘은 3번 알고리즘 때문에 증가 수열의 "길이"는 구할 수 있지만, 이 방법으로 구한 LIS는 실제 얻을 수 있는 LIS와 다르다!!!
그림으로 확인해보자.
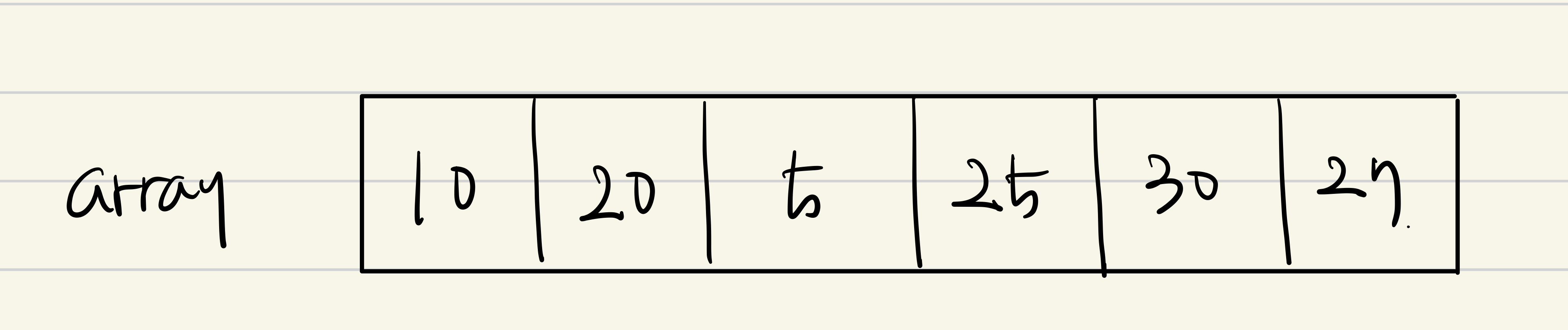
위와 같이 array가 주어졌다고 생각해보자.

먼저 11053번 처럼 dp를 이용해 풀면 위와 같고 LIS의 길이는 4임을 알 수 있다.
다음으로 위에서 설명한 알고리즘을 그림으로 보자.

먼저 dp를 이용하는 것이 아니기 때문에 dp 배열이라고 하지 않는다. result 배열은 현재 증가수열을 보여주는 배열이다.
첫 번째 값인 10은 비교할 값이 없으므로 그냥 값을 넣어주거나, result 배열의 맨 처음에 음의 무한대 값이 있다고 가정하고 시작한다.
-무한대보다 10이 크므로 그냥 값을 뒤에 붙이면 증가 수열을 만들 수 있다.
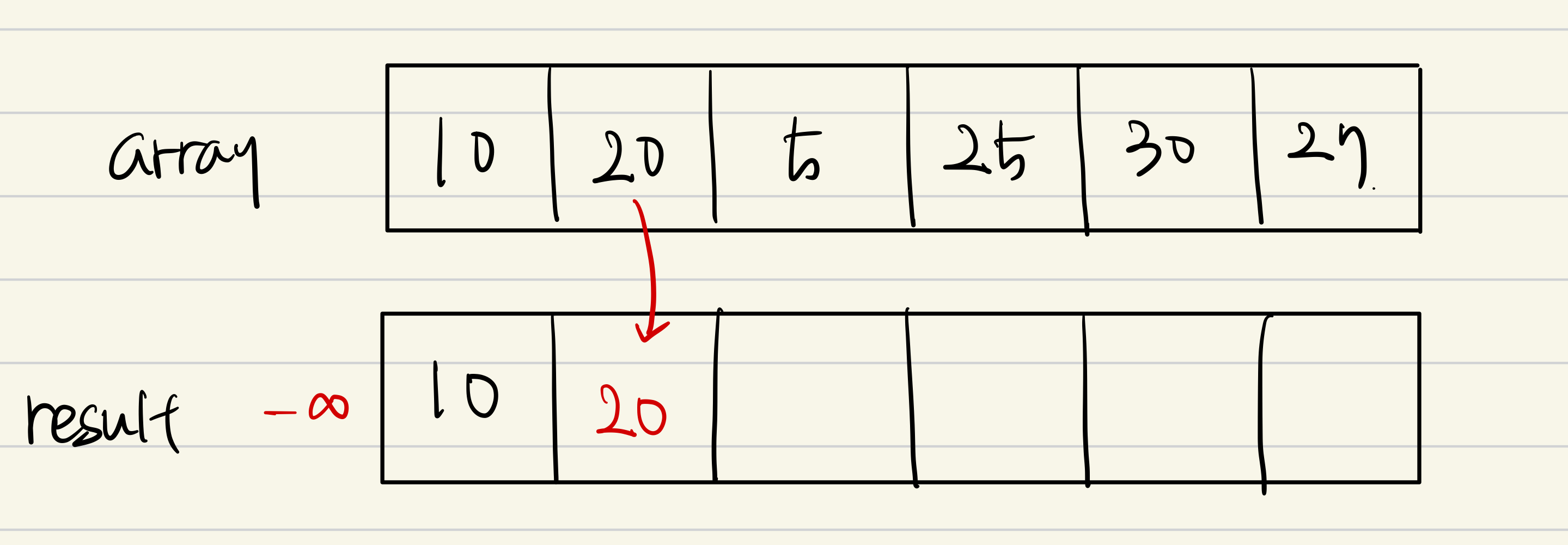
다음 입력 값인 20을 보자.
20은 10보다 크므로 10 뒤에 바로 붙어주면 증가수열을 만들 수 있다.

다음 값으로 5가 들어왔다. 5는 어디에 들어가야할까?
먼저 증가수열의 마지막 값인 20보다 작으므로 알고리즘의 3번을 따라야 한다.
기존 증가 수열은 -무한, 10, 20이었으므로 5보다 작지 않은 최솟값은 10이다. 따라서 10과 5를 치환한다.
말은 잘했지만 사실 나도 왜 이렇게 하는지, 왜 이 방법으로 "길이"만큼은 확실하게 구할 수 있는지 정확하게 이해하지 못했다
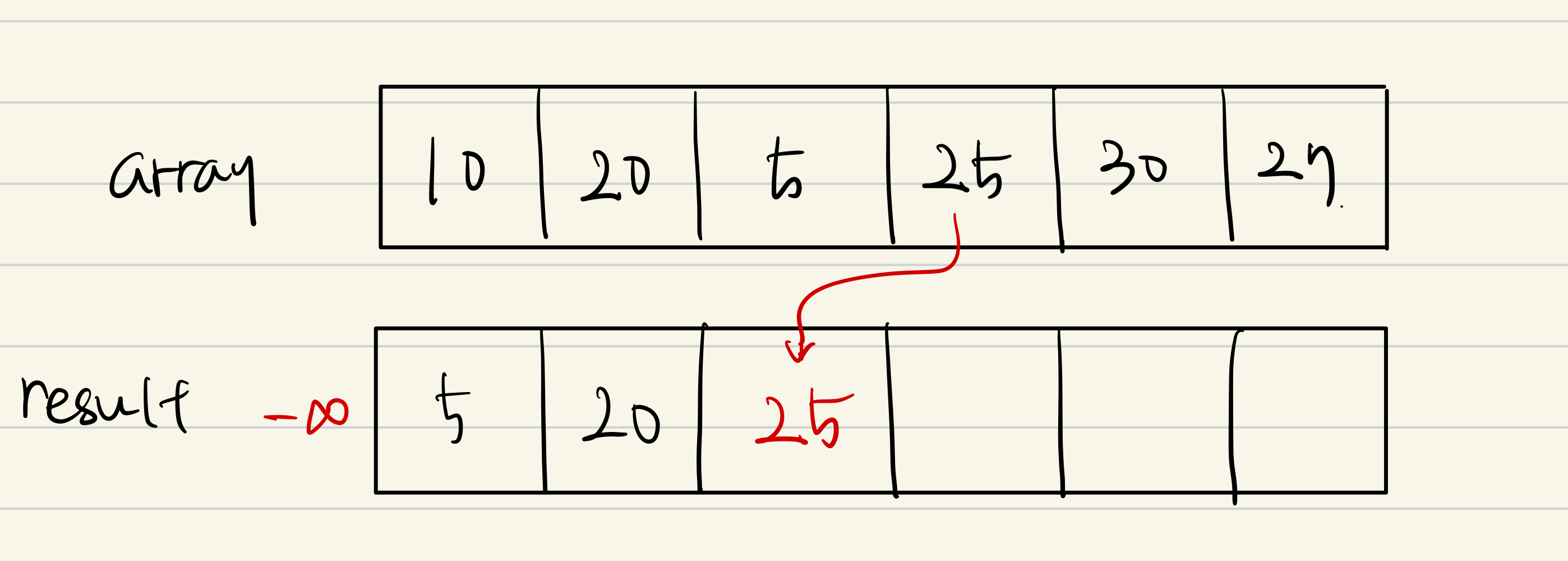
다음 값은 25이고 이는 증가수열의 마지막은 20보다 크므로 증가수열의 끝에 붙여주면 된다.
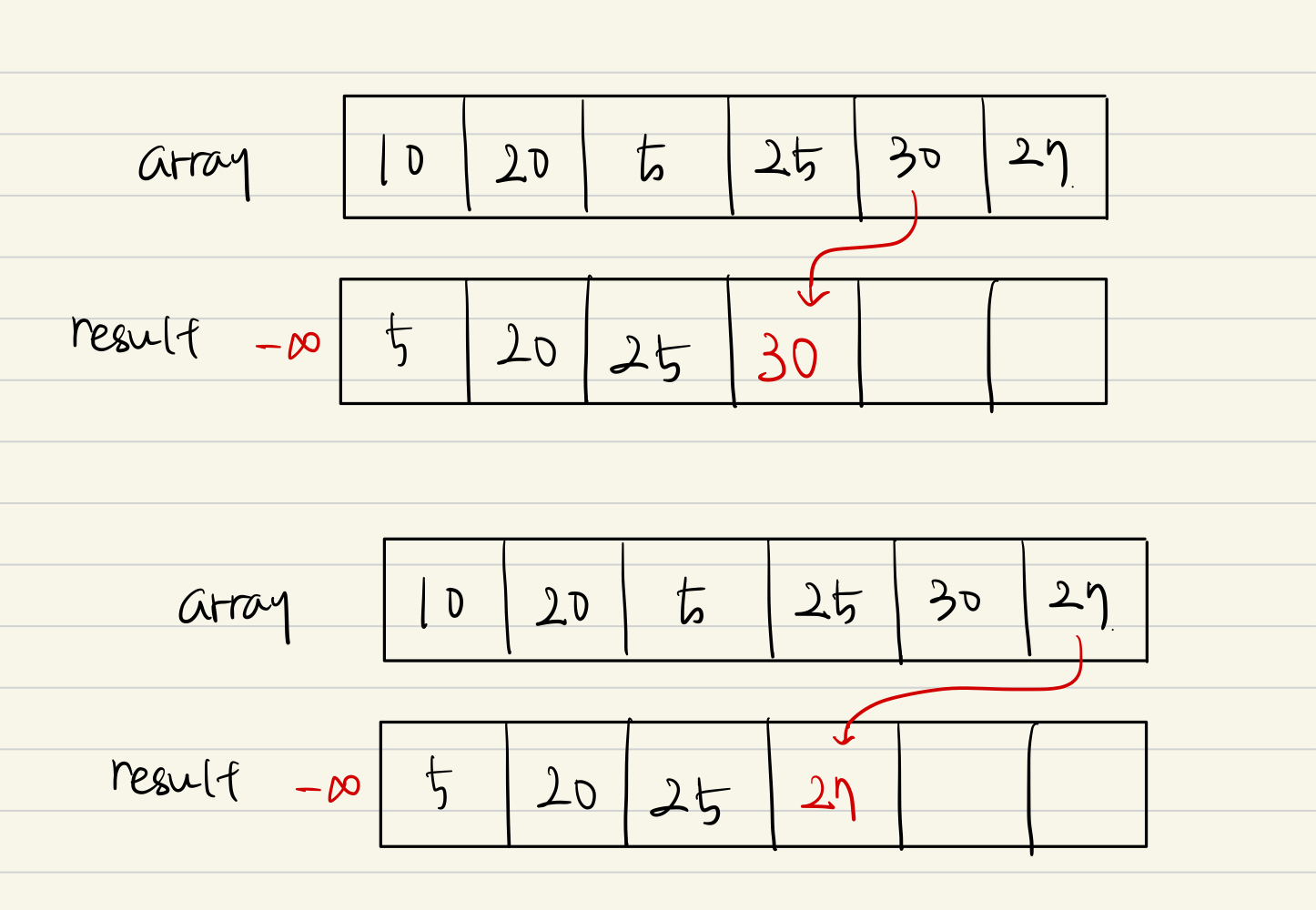
30도 마찬가지이다. 25보다 크므로 바로 뒤에 붙여주면 증가수열을 만들 수 있다.
다음은 27이다.
27은 30보다 작으므로 27보다 작지 않은 수 중 최솟값을 찾아 치환해야 하는데 이는 30이다.
이 때, 27이 30과 바뀌는 것이 정당한 이유는, 이 이후에 28이라는 값이 온다고 가정했을 때 만약 30이 증가수열의 끝이라면 28을 받을 수 없지만 증가수열의 끝이 27이라면 28을 붙일 수 있어 증가수열의 크기를 증가시킬 수 있기 때문이다.
이로서 증가수열 길이 찾기가 끝나고 총 증가수열의 길이는 4임을 알 수 있다. (맨 처음 알고리즘 수행을 위해 넣었던 -무한대는 취급하지 않는다.)
다시한번 정리하면, 이 알고리즘의 포인트는
1. 증가수열의 마지막 값보다 작은 값이 왔을 때, 알고리즘 수행을 위한 값을 빠르게 찾기 위해 이진 탐색을 사용한다는 점
2. 구한 LIS가 정확한 LIS가 아니고 LIS의 길이만을 구할 수 있는 알고리즘이라는 점
을 꼽을 수 있겠다.
개인적인 생각을 남기자면, 필자가 "이해 안간다는 3번 알고리즘"에 의해 30과 27이 바뀌는 것이 정당한 이유는 납득이 가지만 5가 저 사이로 끼어드는 점은 이해가 잘 안간다.
복습과 납득이 필요한 문제였다.
아래는 파이썬으로 해결한 코드이다.
이진 탐색 함수를 직접 만들지 않고 정렬되어있는 데이터에서 값이 들어가는 인덱스를 구해주는 bisect 라이브러리를 사용한 코드를 같이 첨부한다.
# 가장 긴 증가하는 부분수열 2 https://www.acmicpc.net/problem/12015
N = int(input())
array = list(map(int, input().split()))
dp = []
dp.append(float('-inf'))
def BinarySearch(par_array, start_idx, end_idx, target):
if start_idx > end_idx:
return start_idx
mid = (start_idx + end_idx) // 2
if par_array[mid] == target:
return mid
elif par_array[mid] > target:
return BinarySearch(par_array, start_idx, mid-1, target)
elif par_array[mid] < target:
return BinarySearch(par_array, mid+1, end_idx, target)
for arr in array:
if arr > dp[-1]:
dp.append(arr)
elif arr == dp[-1]:
continue
elif arr < dp[-1]:
temp = BinarySearch(dp, 0, len(dp)-1, arr)
dp[temp] = arr
print(len(dp)-1)
## 이진 탐색 함수를 직접 만들지 않고 bisect 라이브러리를 이용해 파이써닉하게 짠 코드
# from bisect import bisect_left
# N = int(input())
# array = list(map(int, input().split()))
# dp = []
# dp.append(float('-inf'))
# for arr in array:
# if arr > dp[-1]:
# dp.append(arr)
# elif arr < dp[-1]:
# temp_idx = bisect_left(dp, arr)
# dp[temp_idx] = arr
# elif arr == dp[-1]:
# continue
# del dp[0]
# print(len(dp))
# for i in dp:
# print(i, end=' ')'[PS]' 카테고리의 다른 글
| [boj] 평범한 배낭_12865 (0) | 2021.03.29 |
|---|---|
| [boj] 안녕_1535 (0) | 2021.03.29 |
| [boj] 미로 탐색_2178 (0) | 2021.03.07 |
| [boj] LCS2_9252 (0) | 2021.03.04 |
| [boj] 퇴사_14501 (0) | 2021.02.25 |


