
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 9663
- 백준 12015
- 미로탐색
- 백준 2606
- 프로그래머스
- 알고리즘
- BOJ 2606
- 가장 긴 증가하는 부분수열
- 파이썬
- 백준 9252
- 평범한 배낭
- 냅색
- list
- 백준
- 백준 1535
- LCS2
- dfs
- 12865
- 소수찾기
- 타겟 넘버
- BFS
- python
- 데카르트 곱
- 증가하는 부분수열 2
- 8-queen
- 백준_2178
- 2606
- boj 11053
- 대소비교
- 리스트
- Today
- Total
Devlog_by_0giru
[boj] LCS2_9252 본문
최장 공통 부분 수열이라고 부르는 알고리즘이다.
영어로 LCS(Longest Common Subsequence) 라고 하는데, 최장 공통 부분 문자열도 LCS라고 부르는 모양이다.
둘의 차이점은 공통 부분이 연속하느냐, 마느냐인 것 같다. 이 부분에 대해서는 나중에 후자인 LCS를 공부할 때 다시 수정할 계획이다.
백준 9252번을 풀기 위해 필요한 알고리즘인데, 아주 클래식한 알고리즘이기도 하니 필수적으로 알고 있어야 한다. https://www.acmicpc.net/problem/9252
LCS 알고리즘을 풀기 위해서는 검사할 두 문자열의 앞에 공백 문자열(혹은 더미 문자열)을 하나씩 붙여주어야 한다.
검사할 문자열이 ACAYKP, CAPCAK라고 하자. (백준 9252번의 테스트 케이스이다.)

위 표에서 나온 것과 같이 검사할 두 문자 앞에 공백 문자열을 포함해서 비교하는 것이 핵심이다.
그럼 검사를 시작하자.

첫 번째 문자열인 ACAYKP와 두 번째 문자열의 공백 문자열과의 겹치는 문자의 수이다.
공백문자열과 동일한 문자는 없기 때문에 모두 0 이다.

두 번째 문자열의 C와 겹치는 문자의 수 이다.
첫 번째 문자열의 A를 지나 C에서 처음으로 겹쳐 1이 되었고 이후에는 C와 CA, CAY, CAYK, CAYKP가 겹치는 수 이므로 모두 1을 유지함이 자명하다.
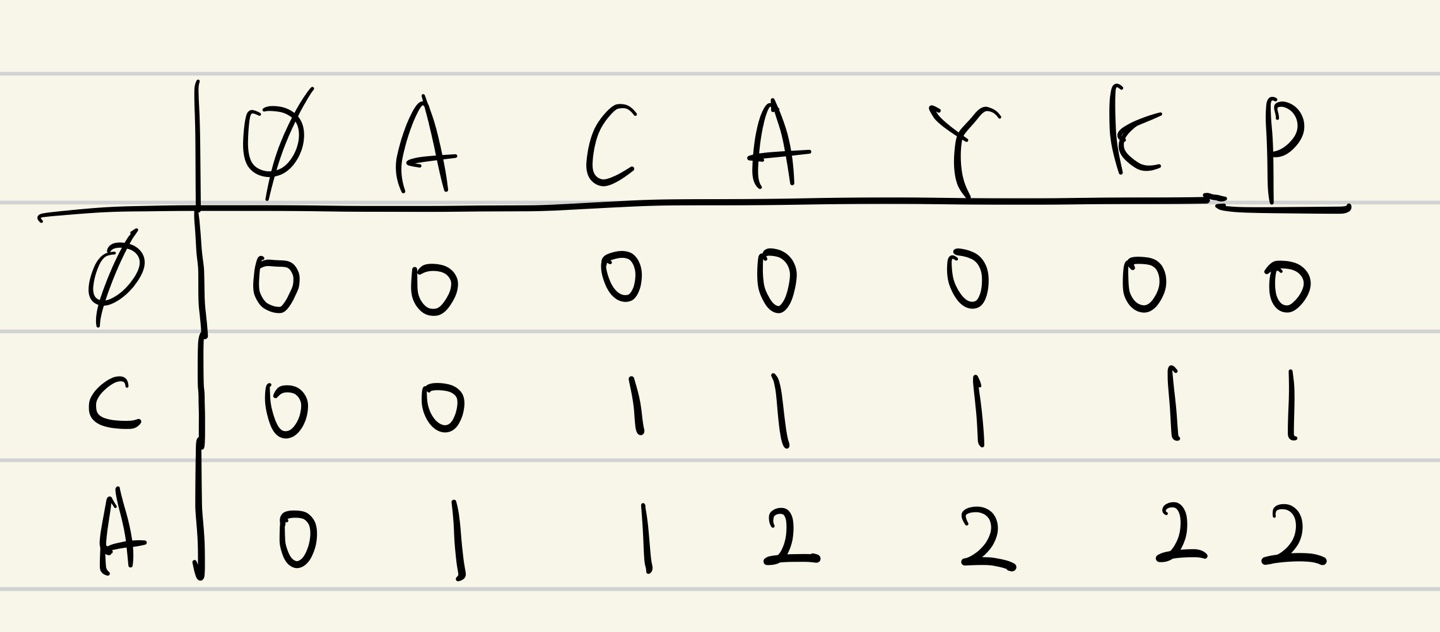
다음은 CA와 ACAYKP가 겹치는 문자를 비교해보자.
CA는 ACAYKP와 같이 공통되므로 겹치는 문자의 수가 2로 증가하고 뒤에는 없어 그대로 유지된다.

다음은 첫 번째 문장에서 P까지 등장했다.
여기서는 표시한 빨간색과 주황색 원을 유심히 봐야 한다.
빨간색 화살표로 표시한 부분을 보면 P와 A의 비교인데도 숫자가 0이 아니라 1이다.
왜냐하면, 이는 단순히 P와 A를 비교하는 것이 아니라 CAP와 A를 비교하는 것이기 때문이다.
이를 첫 번째 문자열의 관점과 두 번째 문자열의 관점에서 본다면,
1. CAP와 공백 문자열에서 CAP와 A문자열의 비교로 변화
2. CA와 A 문자열의 비교에서 CAP와 A 문자열의 비교로 변화
라고 생각할 수 있다.
그렇다면 0에서 변화를 따져야할지 혹은 1에서 변화를 따져야하는지 결정해야하는데, 둘 중의 큰 수를 따르면 된다.
왜냐하면 후자의 경우에는 자연스럽게 1이 유지되어야 하고, 전자의 경우 이전에 등장한 문자열을 따지기 때문에 그 내용이 후자의 경우를 포함해야 하기 때문이다.
또, 이해를 위해 윗줄에서 비교한 A와 CA를 생각해보자.
A와 CA는 이미 A가 겹쳐 숫자가 1로 증가한 상태이다. 그런데, 여기서 CA에 (A와 겹치지 않는) P가 붙는다고 해서 숫자의 변동이 생기지 않는다. 그렇기 때문에 이 때 CA와 A를 비교한 1이 CAP와 A를 비교한 1로 그대로 옮겨와도 상관이 없는 것이다.
그리고 주황색 원을 보자.
주황색 원으로 표시된 부분은 첫 번째 문자열의 P와 두 번째 문자열의 P가 겹치는 구간이다.
두 문자열에서 P가 등장하기 까지는 가장 마지막까지 겹친 문자열의 수는 주황색 원으로 싸인 2였으나 두 문자열에서 P가 동시에 등장함으로써 2에서 3으로 1이 증가한 것으로 이해할 수 있다.
이를 정리하면 아래와 같다.
두 문자열의 문자를 하나씩 비교해가면서 겹치는 문자열이 등장한다면, 해당하는 칸의 왼쪽 위에서 1을 더하면 되고, 문자가 겹치지 않는다면 위와 왼쪽 중 큰 수를 따르면 된다.
이 내용을 통해 최종적으로 정리한 표는 아래와 같다.

따라서 두 수열을 비교해 얻은 결과는 4이고, 실제로 겹치는 부분을 비교해보면 ACAYKP, CAPCAK로 4임을 알 수 있다.
문제에서는 수와 공통되는 부분 문자열을 동시에 출력하라고 요구하는데, 겹치는 수를 구해주는 것과 완전 동일한 알고리즘으로 구할 수 있었다.

위 표로 정리한 내용을 코딩을 통해 구현하기 위해 이중 리스트를 이용했다.
# LCS2 https://www.acmicpc.net/problem/9252
str1 = '0'+input()
str2 = '0'+input()
LCS_len = [[] for i in range(len(str2))]
LCS_str = [[] for i in range(len(str2))]
for i in range(len(str2)):
if str2[i] == '0':
for j in range(len(str1)):
LCS_len[i].append(0)
LCS_str[i].append('0')
else:
for k in range(len(str1)):
if str1[k] == '0':
LCS_len[i].append(0)
LCS_str[i].append('0')
else:
if str2[i] != str1[k]:
LCS_len[i].append(max(LCS_len[i][k-1], LCS_len[i-1][k]))
if LCS_len[i][k-1] >= LCS_len[i-1][k]:
LCS_str[i].append(LCS_str[i][k-1])
elif LCS_len[i][k-1] < LCS_len[i-1][k]:
LCS_str[i].append(LCS_str[i-1][k])
elif str2[i] == str1[k]:
LCS_len[i].append(LCS_len[i-1][k-1] + 1)
LCS_str[i].append(LCS_str[i-1][k-1] + str2[i])
def getPos():
count = 0
for i in range(len(str2)):
for j in range(len(str1)):
if LCS_len[i][j] >= count:
count = LCS_len[i][j]
return (i, j)
result = getPos()
if LCS_len[result[0]][result[1]] == 0:
print(0)
exit
else:
print(LCS_len[result[0]][result[1]])
print(LCS_str[result[0]][result[1]][1:])'[PS]' 카테고리의 다른 글
| [boj] 가장 긴 증가하는 부분 수열2_12015 (0) | 2021.03.08 |
|---|---|
| [boj] 미로 탐색_2178 (0) | 2021.03.07 |
| [boj] 퇴사_14501 (0) | 2021.02.25 |
| [boj] 가장 긴 증가하는 부분수열_11053 (완전탐색, DP) (1) | 2021.02.24 |
| [boj] 치킨 배달_15686 (0) | 2021.02.23 |


